SQL + R
Connecting SQL in RStudio/RMarkdown
Tom Choi
library(RPostgreSQL)
library(RPostgres)
library(flextable)
library(tidyverse)
library(officer)
library(wesanderson)con <- dbConnect(RPostgres::Postgres(),
host='localhost',
port='5432',
dbname='dvdrental',
user='postgres',
password=pw)
rm(pw) # removes the password
formats <- list(
"dod" = function(x) ifelse(is.na(x), x, sprintf("%.0f%%", x)),
"current_day" = function(x) ifelse(is.na(x), x, sprintf("$%.0f", x)),
"prev_day" = function(x) ifelse(is.na(x), x, sprintf("$%.0f", x)),
"film_revenue" = function(x) ifelse(is.na(x), x, sprintf("$%.0f", x)),
"film_revenue_pct" = function(x) ifelse(is.na(x), x, sprintf("%.0f%%", x))
)
std_border = fp_border(color="gray")
flextables <- function(data){
headers <- tibble(col_keys = colnames(data),
line1 = colnames(data) %>%
recode(
"actor_category" = "Category",
"count" = "Count",
"watcher_category" = "Category",
"film_id" = "Film ID",
"film_revenue" = "Total revenue ($)",
"film_revenue_pct" = "Total revenue (%)",
"store_id" = "Store ID",
"date" = "Date",
"current_day" = "Daily revenue",
"prev_day" = "Lag-1 revenue",
"dod" = "DoD growth"
)
)
flextable(data) %>%
{rlang::inject(set_formatter(., !!! formats))} %>%
set_header_df(mapping = headers, key = "col_keys") %>%
theme_booktabs() %>%
hline(part="body", border = std_border ) %>%
autofit()
}Database overview
Description
The Sakila Database holds information about a company that rents movie DVDs. For this project, we will be querying the database to gain an understanding of the customer base, such as what the patterns in movie watching are across different customer groups, how they compare on payment earnings, and how the stores compare in their performance.
And here is the Entity-relationship (ER) diagram for the DVD Rental database is provided below.

Tables
actor: contains actors data including first name and last namefilm: contains films data such as title, release year, length, rating, etcfilm_actor: contains the relationships between films and actorscategory: contains film’s categories datafilm_category: containing the relationships between films and categoriesstore: contains the store data including manager staff and addressinventory: stores inventory datarental: stores rental datapayment: stores customer’s paymentsstaff: stores staff datacustomer: stores customer’s dataaddress: stores address data for staff and customerscity: stores the city namescountry: stores the country names
Source
Practice Questions
Question 13
Please write a query to return the number of actors whose first name starts with ‘A’, ‘B’, ‘C’, or others. The order of your results doesn’t matter. You need to return 2 columns:
- First column: a group of actors based on the first letter of their
first_name, use the following:
a_actors,b_actors,c_actors,other_actorsto represent their groups. - Second column: the number of actors whose first name matches the pattern.
q13_dataframe <- dbGetQuery(con,
"with cte1 as (
select *, case
when first_name like 'A%' then 'a_actors'
when first_name like 'B%' then 'b_actors'
when first_name like 'C%' then 'c_actors'
else 'other_actors'
end as actor_category
from actor a
)
select actor_category, count(*)
from cte1
group by actor_category
order by actor_category
;"
)
flextables(q13_dataframe)Category | Count |
a_actors | 13 |
b_actors | 8 |
c_actors | 18 |
other_actors | 161 |
q13_dataframe %>% mutate(count = as.integer(count)) %>%
ggplot(aes(x=actor_category, y=count,
label=count, vjust=-0.5)) +
geom_col(fill=wes_palette("Darjeeling1", n=4)) +
scale_y_continuous(expand = expansion(mult = c(0, .2))) +
xlab("Category") +
ylab("Count") +
geom_text()
Question 15
Please write a query to return the number of fast movie watchers vs slow movie watchers. The orders of your results doesn’t matter. A customer can only rent one movie per transaction.
- fast movie watcher: by average return their rentals within 5 days.
- slow movie watcher: takes an average of >5 days to return their rentals.
- Most customers have multiple rentals over time, you need to first compute the number of days for each rental transaction, then compute the average on the rounded up days. (e.g., if the rental period is 1 day and 10 hours, count it as 2 days.)
- Skip the rentals that have not been returned yet (e.g., rental_date IS NULL)
q15_dataframe <- dbGetQuery(con,
"with cte1 as (
select *, return_date - rental_date as rental_period
from rental
),
cte2 as (
select *, extract(days from rental_period)+1 as rental_days
from cte1
),
cte3 as (select customer_id, avg(rental_days) avg_rental
from cte2
where rental_days is not null
group by customer_id
)
,
cte4 as (
select *, case
when avg_rental > 5 then 'slow movie watcher'
else 'fast movie watcher'
end watcher_category
from cte3
--;
)
select watcher_category, count(customer_id)
from cte4
group by watcher_category
;
"
)
flextables(q15_dataframe)Category | Count |
slow movie watcher | 487 |
fast movie watcher | 112 |
q15_dataframe %>% mutate(count = as.integer(count)) %>%
ggplot(aes(x=watcher_category, y=count,
label=count, vjust=-0.5)) +
geom_col(fill = wes_palette("Darjeeling2", n=2)) +
scale_y_continuous(expand = expansion(mult = c(0, .2))) +
xlab("Category") +
ylab("Count") +
geom_text()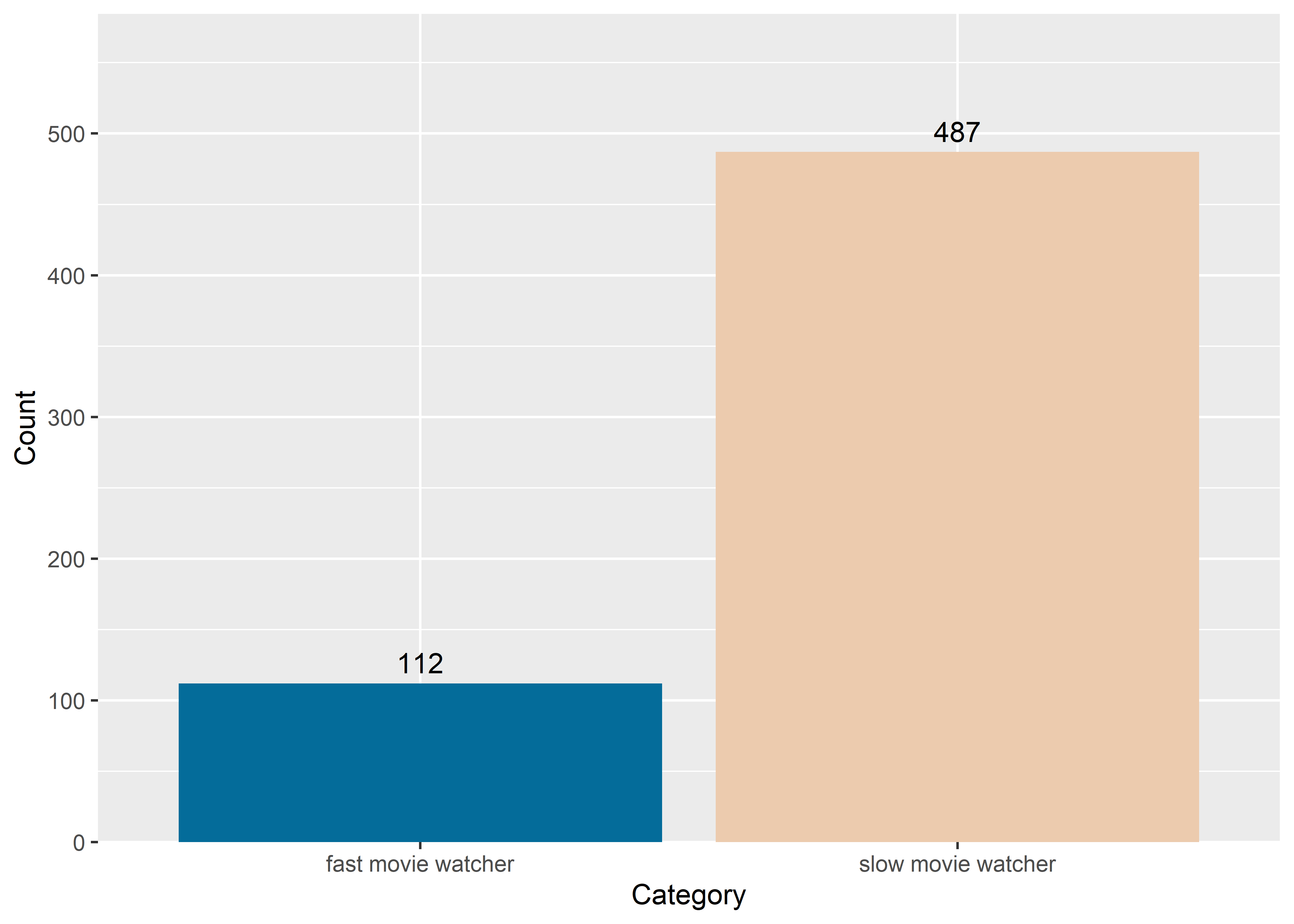
Question 58
Write a query to return the percentage of revenue for each of the following films: film_id <= 10
- Formula: revenue (film_id x) * 100.0/ revenue of all movies
- The order of your results doesn’t matter
q58_dataframe <- dbGetQuery(con,
"with cte1 as (
select distinct film_id,
sum(amount) over(partition by film_id) film_revenue
from payment p
left join rental r
using (rental_id)
left join inventory i
using (inventory_id)
where film_id <= 10
)
select *,
film_revenue *100.0 / sum(film_revenue) over() film_revenue_pct
from cte1
order by film_id
;")
flextables(distinct(q58_dataframe))Film ID | Total revenue ($) | Total revenue (%) |
1 | $34 | 5% |
2 | $53 | 7% |
3 | $35 | 5% |
4 | $84 | 11% |
5 | $48 | 6% |
6 | $112 | 15% |
7 | $83 | 11% |
8 | $87 | 12% |
9 | $72 | 10% |
10 | $132 | 18% |
distinct(q58_dataframe) %>%
ggplot(aes(x=film_id, y=film_revenue,
label=sprintf("$%.0f", film_revenue), vjust=-0.5)) +
geom_col(fill = c(wes_palette("GrandBudapest1"),
wes_palette("GrandBudapest2"),wes_palette("Rushmore1", n=2)
)) +
scale_x_continuous(breaks=seq(1, 10, 1)) +
scale_y_continuous(expand = expansion(mult = c(0, .2))) +
xlab("Film ID") +
ylab("Total revenue ($)") +
geom_text()
Question 80
Please write a query to return DoD(day over day) growth for each store from April 24, 2007 (inclusive) to April 31, 2007 (inclusive).
DoD: (current_day/ prev_day -1) * 100.0- Multiply dod growth to 100.0 to get percentage of growth
- Use ROUND to convert dod growth to the nearest integer
q80_dataframe <- dbGetQuery(con,
"with cte1 as(
select store_id,
date(payment_date) date,
sum(amount) current_day
from payment p
left join rental r
using (rental_id)
left join inventory i
using (inventory_id)
where payment_date >= '2007-04-01' and payment_date <= '2007-04-30'
group by store_id, date(payment_date)
),
cte2 as (
select *, lag(current_day) over(partition by store_id order by date) prev_day
from cte1
)
select *, round((current_day/prev_day-1)*100.0) DoD
from cte2
;"
)
flextables(q80_dataframe) %>%
merge_v(j = c("store_id")) %>%
valign(j = c("store_id"), valign = "top") %>%
align(align="center", part="header")Store ID | Date | Daily revenue | Lag-1 revenue | DoD growth |
1 | 2007-04-05 | $119 | ||
2007-04-06 | $1044 | $119 | 779% | |
2007-04-07 | $1011 | $1044 | -3% | |
2007-04-08 | $1135 | $1011 | 12% | |
2007-04-09 | $971 | $1135 | -15% | |
2007-04-10 | $981 | $971 | 1% | |
2007-04-11 | $1029 | $981 | 5% | |
2007-04-12 | $995 | $1029 | -3% | |
2007-04-26 | $155 | $995 | -84% | |
2007-04-27 | $1309 | $155 | 746% | |
2007-04-28 | $1175 | $1309 | -10% | |
2007-04-29 | $1458 | $1175 | 24% | |
2 | 2007-04-05 | $155 | ||
2007-04-06 | $1034 | $155 | 568% | |
2007-04-07 | $974 | $1034 | -6% | |
2007-04-08 | $1092 | $974 | 12% | |
2007-04-09 | $1097 | $1092 | 0% | |
2007-04-10 | $993 | $1097 | -10% | |
2007-04-11 | $912 | $993 | -8% | |
2007-04-12 | $936 | $912 | 3% | |
2007-04-26 | $193 | $936 | -79% | |
2007-04-27 | $1365 | $193 | 609% | |
2007-04-28 | $1448 | $1365 | 6% | |
2007-04-29 | $1260 | $1448 | -13% |